Every research team has the same dirty secret: most of the insights they produce disappear.
Not because the research was bad. Not because nobody cared. But because there is no system to capture, organize, and resurface qualitative findings when they matter most — which is almost always after the original study wraps up.
A product manager kicks off discovery for a new feature. Somewhere in the organization, a researcher conducted 30 interviews on exactly this topic eighteen months ago. But the findings live in a Google Slides deck buried in someone's Drive folder, tagged with a project name nobody remembers. So the PM commissions new research. The team spends six weeks and tens of thousands of dollars rediscovering what was already known.
This is not an edge case. This is the default operating mode for the vast majority of research teams. And it is an enormous, compounding waste.
A qualitative research repository — a structured, searchable library of reusable research insights — is the fix. But most attempts at building one fail, not because the idea is wrong, but because the execution misses what actually makes a repository usable.
This guide covers how to build one that works. Not a graveyard of old reports, but a living knowledge base that gets more valuable with every study you add to it.
Why Research Insights Get Lost
Before we talk solutions, we need to be honest about the problem. Research insights get lost for structural reasons, not because individuals are careless.
The deliverable trap. Most research is organized around deliverables — a report, a deck, a readout. Once the deliverable ships and the stakeholders nod along in the meeting, the project is "done." The insights are frozen inside that artifact, formatted for a specific audience at a specific moment in time. They are not formatted for retrieval.
Project-based thinking. When research is organized by project, findings are siloed by the question that prompted them. But the richest insights are often tangential — a usability study reveals an unmet need, a pricing study surfaces a mental model about value. These adjacent findings have no home in a project-based structure. As we explored in our piece on continuous discovery vs. project-based research, this project-centric mindset creates blind spots that compound over time.
Tool fragmentation. Transcripts in one tool. Codes in a spreadsheet. Themes in a Miro board. Highlights in Dovetail. Final report in Google Slides. The insight journey touches five or more tools, and none of them talk to each other. There is no single source of truth.
Turnover and institutional amnesia. Researchers leave. PMs rotate teams. Agencies finish engagements. When the person who did the research is gone, the contextual knowledge that made those findings actionable leaves with them. The artifacts remain, but they are shells — data without interpretation.
The spreadsheet ceiling. Many teams start by logging insights in spreadsheets or Notion databases. This works for the first 50 entries. By the time you hit 200, search is broken, tagging is inconsistent, and nobody trusts the data. We wrote about this ceiling in moving beyond spreadsheets for qualitative data analysis — the same limitations that plague analysis also plague storage and retrieval.
The net result: your organization pays for research once but captures the value of that research for about six weeks. After that, it is effectively gone.
What a Research Repository Actually Is
Let us define terms clearly, because "research repository" means different things to different people.
A qualitative research repository is not a file storage system. It is not a shared drive with folders. It is not a wiki page where someone pastes a summary after each study.
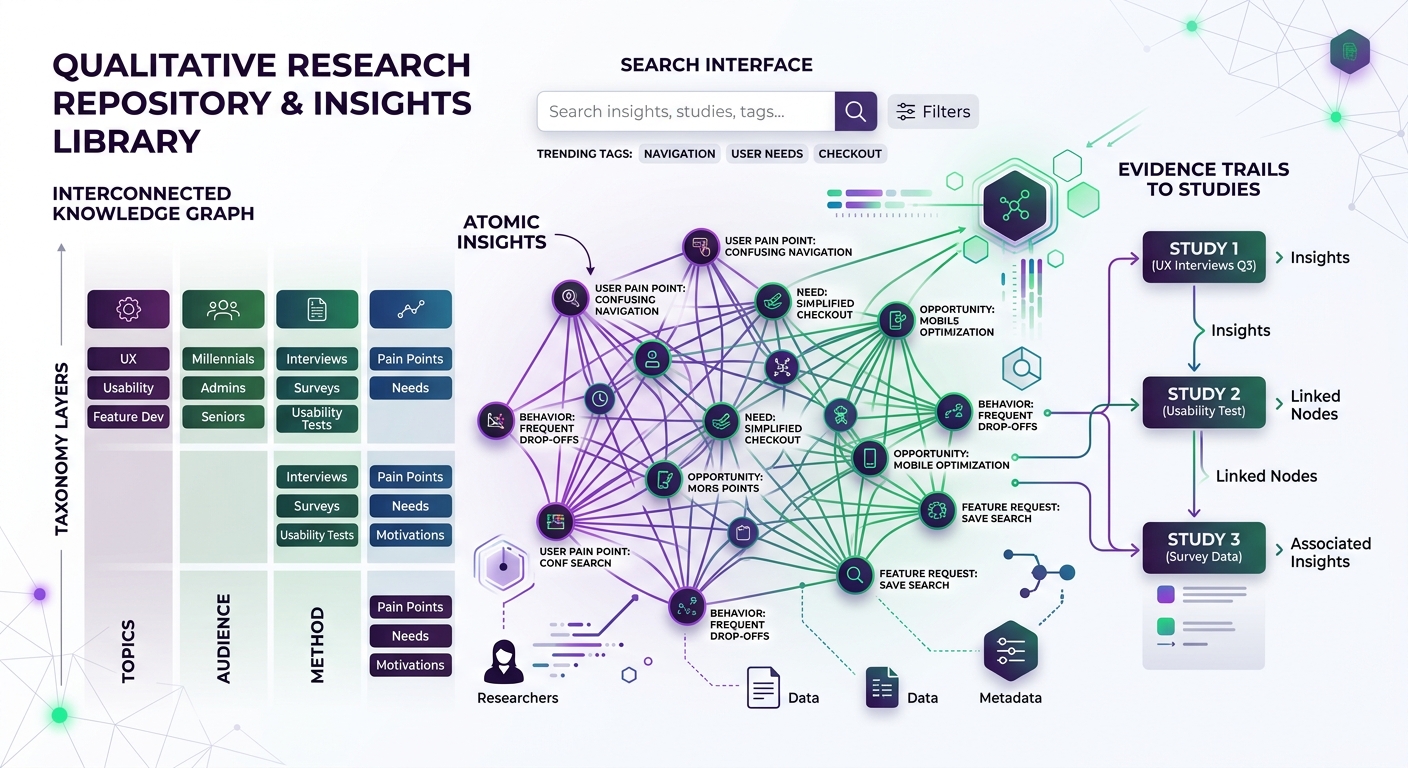
A proper research repository is a structured knowledge base where individual insights — atomic, tagged, contextualized units of evidence — can be stored, searched, connected, and reused across projects, teams, and time.
The key architectural principles:
Atomic insights, not monolithic reports. The unit of storage is the individual insight or finding, not the study. A single interview might yield twelve distinct insights that are relevant to twelve different product areas. Each one needs to be independently retrievable.
Rich metadata and taxonomy. Every insight carries structured metadata: what study it came from, when it was collected, what method was used, what participant segment it represents, what product area it relates to, what confidence level it carries, and what themes it connects to.
Evidence trails. Each insight links back to its source evidence — the specific transcript passage, the exact survey response, the video clip. This is not optional. Insights without evidence are just opinions with a research veneer.
Searchability by concept, not just keyword. A PM wondering about "why users abandon onboarding" should find relevant insights even if none of them use the word "abandon." This requires semantic understanding, not just text matching.
Living, not archival. A repository is not a warehouse where insights go to retire. It is an active system where new research builds on old research, where patterns emerge across studies, and where the act of adding new insights surfaces connections to existing ones.
The Taxonomy Problem (And How to Solve It)
Taxonomy is where most repository initiatives stall. Teams spend months debating the perfect tagging structure, then nobody uses it because it is too complex, or everyone uses it differently because it is too vague.
Here is the pragmatic approach that actually works:
Start With Three Dimensions
You need exactly three mandatory tagging dimensions to start. Everything else is optional enrichment.
1. Product area or domain. Where does this insight apply? This could map to your product's information architecture, your team structure, or your customer journey stages. Keep it to 10-15 top-level categories maximum. Examples: Onboarding, Core Workflow, Billing, Mobile Experience, Enterprise Admin.
2. Insight type. What kind of finding is this? Use a simple typology:
- Need (unmet user need or job-to-be-done)
- Behavior (observed pattern of action)
- Pain point (friction, frustration, or failure)
- Mental model (how users think about a concept)
- Motivation (why users do what they do)
- Preference (stated or revealed preference)
3. Participant segment. Who does this insight come from? This could be persona-based, plan-tier-based, demographic, or behavioral. The key is consistency across studies.
Let AI Handle the Rest
Here is where modern tooling changes the game. Traditional repositories required researchers to manually tag every insight, which meant tagging was inconsistent, incomplete, and a drag on productivity.
AI-powered coding flips this. When you run qualitative data through an AI coding engine, you get consistent, exhaustive tagging as a byproduct of analysis. Every insight is coded against your taxonomy automatically. The researcher reviews and refines rather than starting from scratch.
This is one of the most underappreciated benefits of AI-powered qualitative analysis — it does not just speed up analysis, it produces structured, machine-readable output that feeds directly into a searchable repository. The coding is not a separate step you do for the repository. The coding IS the repository being built.
With 14 research lenses available on Qualz, every piece of data is analyzed from multiple theoretical and practical angles simultaneously. The output is not just "here are some themes" — it is a rich, multi-dimensional coding of every data point that becomes instantly searchable and connectable.
Evolve the Taxonomy Iteratively
Do not try to design the perfect taxonomy upfront. Start with your three dimensions, run five studies through the system, then review what is missing. Add tags that would have helped you find things. Remove tags nobody uses. Merge tags that overlap.
The taxonomy should stabilize after 10-15 studies. At that point, you will have a structure that reflects how your organization actually thinks about its users, not how you theoretically imagined you should.
Connecting Past Research to New Questions
The real value of a repository is not storage — it is retrieval. Specifically, it is the ability to start any new research initiative with everything your organization already knows.
This changes the research workflow fundamentally:
Before a new study: Query the repository. Before writing a discussion guide or designing a survey, search the repository for everything relevant to your research question. You will often find that 30-50% of what you need to learn is already known. This does not eliminate the need for new research — it focuses it. You skip the basics and go deeper.
During analysis: Connect to existing patterns. As you code new data, the system surfaces connections to past findings. A participant mentions something about pricing confusion, and the repository shows you that three previous studies flagged similar confusion in a different context. Suddenly your N=8 study is connected to an N=40 evidence base.
After a study: Enrich the existing base. New findings do not just get added to the repository — they update and strengthen existing insights. A theme identified in one study gets confirmed, nuanced, or challenged by the next study. The repository captures this evolution.
This is what transforms research from a series of disconnected projects into a compounding knowledge asset. Each study makes every previous study more valuable, and every future study starts from a higher baseline.
For teams practicing continuous discovery, this is essential infrastructure. As we discussed in continuous discovery vs. project-based research, the continuous model only works if there is a system to accumulate and connect findings over time. Without a repository, continuous discovery is just a series of small projects with no connective tissue.
The Research Repository Maturity Model
Not every team needs a fully automated, AI-powered repository on day one. Here is a four-level maturity model to help you assess where you are and plan your next step.
Level 1: The Filing Cabinet
What it looks like: Research reports and deliverables are stored in a shared drive or wiki with some folder structure. There may be a master spreadsheet that logs completed studies with basic metadata (date, topic, researcher, link to report).
Who can find things: Only the person who did the research, or someone willing to browse through folders and skim documents.
Typical problems:
- Search is keyword-only and unreliable
- No way to find insights across studies
- New team members cannot leverage past work
- Duplicate research is common
What to do next: Start extracting atomic insights from your most recent and most referenced studies. Even pulling 10 key findings from each of your last five studies gives you a starter repository of 50 searchable insights.
Level 2: The Structured Database
What it looks like: Insights are logged in a structured tool (Notion, Airtable, or a purpose-built research repository tool) with consistent metadata. There is an agreed-upon taxonomy. Someone is responsible for maintaining it.
Who can find things: Anyone who knows the taxonomy and is willing to search or browse. Product managers and designers start checking the repository before commissioning new research.
Typical problems:
- Manual tagging is inconsistent across researchers
- The person maintaining it becomes a bottleneck
- Evidence links break as source files move
- Semantic search is limited or nonexistent
What to do next: Introduce AI-assisted coding to standardize tagging. As we detailed in how to analyze open-ended survey responses at scale, AI coding produces consistent output that maps directly to repository structures.
Level 3: The Connected Knowledge Base
What it looks like: The repository is integrated into the research workflow. AI-powered analysis automatically generates tagged, linked insights as a byproduct of every study. New insights are connected to existing ones. The system surfaces relevant past findings when a new research question is defined.
Who can find things: Anyone in the organization, through semantic search. A PM types "why do enterprise customers resist self-serve onboarding" and gets relevant findings from across six studies conducted over two years, ranked by relevance and recency.
Typical problems:
- Cross-team governance is complex
- Confidence decay (how do you weight a two-year-old insight versus a two-month-old one?)
- Repository scale creates noise in search results
What to do next: Implement confidence scoring and insight lifecycle management. Insights should age, be revalidated, or be retired based on the accumulation of new evidence.
Level 4: The Learning System
What it looks like: The repository does not just store insights — it generates them. Pattern detection surfaces emerging themes across studies before any human asks. Contradictions between old and new findings are flagged automatically. The system recommends research questions based on knowledge gaps.
Who can find things: The system finds things for you. When a product team starts planning a new feature, the repository proactively surfaces everything the organization knows about that domain, highlights where evidence is strong versus thin, and suggests what new research would add the most value.
Typical problems:
- Requires significant AI infrastructure investment
- Governance and data quality are critical
- Change management is a real challenge
What to do next: You are at the frontier. Focus on governance, bias detection, and ensuring the system amplifies human judgment rather than replacing it.
Research Ops Maturity and the Repository
A research repository does not exist in isolation. It is one component of a broader research operations (ResearchOps) function, and its success depends on the maturity of that function.
If you have no ResearchOps function: Start with Level 1. Assign one person to maintain a basic insight log. The repository will be only as good as the discipline of the team using it.
If you have a part-time ResearchOps role: Target Level 2. Use standardized templates and a consistent tool. The ResearchOps person maintains taxonomy and quality standards.
If you have a dedicated ResearchOps team: Target Level 3. Invest in AI-powered tooling that generates repository entries as a natural output of the research workflow. The team focuses on governance, quality assurance, and cross-team integration.
If you have a mature, scaled research practice: Target Level 4. Build the learning system. Your competitive advantage is not just what you know — it is how fast you can connect what you know to the decisions that matter.
Building Institutional Memory That Survives Turnover
The most painful failure mode of qualitative research is institutional amnesia. A senior researcher leaves, and 40% of the organization's customer understanding walks out the door with them.
A well-maintained repository is the antidote. But it requires deliberate practices:
Capture context, not just findings. An insight that says "Users find the dashboard confusing" is nearly useless without context. Which users? What were they trying to do? What specifically confused them? What did they expect instead? The repository entry should be rich enough that someone who was not in the room can understand and act on the finding.
Link insights to decisions. When a product decision is informed by research, link the decision back to the supporting insights. This creates a decision audit trail that shows which research drove which outcomes — invaluable for demonstrating research ROI and for understanding why past decisions were made.
Regular curation cycles. Set a quarterly cadence for reviewing and curating the repository. Archive insights that are no longer relevant. Update insights that have been superseded by newer findings. Merge duplicates. Flag contradictions. This is maintenance work, and it is essential. A repository that is never curated eventually becomes a repository that is never trusted.
Onboarding through the repository. When a new researcher or PM joins the team, their onboarding should include a guided tour of the repository. What do we know about our core personas? What are the recurring themes? Where are the knowledge gaps? This gets new team members productive faster and prevents them from rediscovering what the organization already knows.
The goal is to build what we might call institutional research intelligence — the ability to connect past qualitative findings directly to current strategic decisions, regardless of who originally conducted the research.
The Technology Stack for a Modern Research Repository
A practical research repository needs three technical capabilities:
1. Structured storage with flexible schema. Your repository tool needs to accommodate different insight types, metadata structures, and evidence formats without requiring a database migration every time you add a field. This rules out rigid spreadsheets and favors tools designed for semi-structured qualitative data.
2. Semantic search. Keyword search is insufficient for qualitative insights, which use natural language and vary in terminology across researchers. You need vector-based semantic search that understands meaning, not just matching words.
3. AI-powered ingestion. The single biggest predictor of repository success is whether it gets populated consistently. If populating the repository requires manual effort after every study, adoption will erode over time. The winning architecture makes repository population a zero-friction byproduct of analysis, not a separate task.
Qualz is built on this architecture. When you analyze interviews, surveys, or open-ended responses on the platform, the AI coding engine produces structured, tagged, evidence-linked insights that are inherently repository-ready. You do not populate the repository — you just do your research, and the repository builds itself.
Getting Started: The 30-Day Repository Sprint
If you are starting from zero, here is a practical 30-day plan:
Week 1: Foundation
- Choose your three taxonomy dimensions (product area, insight type, participant segment)
- Select your repository tool (or start with a structured Notion database)
- Identify your 5 most-referenced recent studies
Week 2: Seeding
- Extract 10 atomic insights from each of the 5 studies (50 total)
- Tag each insight with your three dimensions
- Link each insight to its source evidence
Week 3: Workflow Integration
- Run your next study through an AI-powered analysis tool
- Ensure the output maps to your repository structure
- Add the new insights to the repository
Week 4: Activation
- Share the repository with your product and design teams
- Run a demo showing how to search for insights
- Collect feedback on what is missing, confusing, or hard to find
- Adjust taxonomy based on real usage
After 30 days, you will have a working repository with 60-80 insights, a tested taxonomy, and early adoption across your organization. That is enough to demonstrate value and build momentum for continued investment.
The Compounding Returns of Research Intelligence
Organizations that build effective research repositories report strikingly consistent benefits:
40-60% reduction in redundant research. When teams can find what is already known, they stop re-answering answered questions and focus new research on genuine unknowns.
Faster time-to-insight for new studies. Starting with existing knowledge means new research goes deeper, faster. The first three interviews in a study are not spent rediscovering baseline context.
Higher research utilization rates. Insights that are findable get used. Research teams report that their work influences 2-3x more decisions when insights are in a searchable repository versus buried in slide decks.
Better cross-functional alignment. When product, design, marketing, and leadership are all drawing from the same evidence base, debates shift from "I think users want X" to "the evidence shows users want X." That is a fundamentally different conversation.
The qualitative research repository is not a nice-to-have tool for mature research teams. It is foundational infrastructure for any organization that wants its investment in understanding customers to compound rather than depreciate. Build it early, build it right, and every study you run from here forward will be worth more than the last.