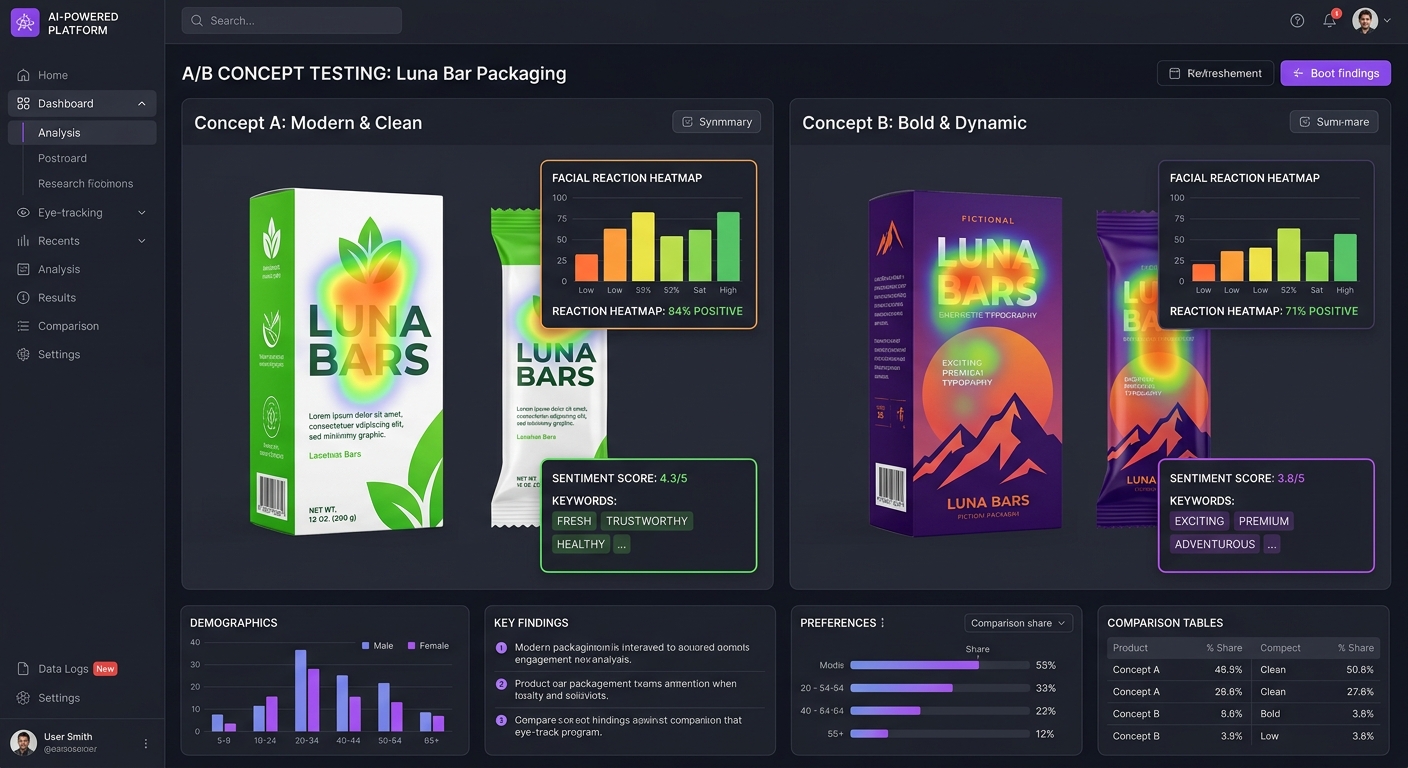
Concept testing is the single most common reason teams run stimulus-based qualitative research. Before committing budget to a new package design, a product variant, or an ad campaign, you need honest reactions from real people — not the polished consensus of an internal review meeting.
The problem? Traditional concept testing is slow, expensive, and riddled with social desirability bias. Respondents tell human moderators what they think the moderator wants to hear. They soften criticism. They over-praise designs that feel "professional" even when those designs fail to communicate the right message.
AI-moderated interviews change the equation. They scale without sacrificing depth, they run 24/7, and — critically — they get more honest reactions because respondents feel less pressure to be polite to a machine.
This guide is a practical playbook for running concept tests with AI interviews. We cover research design choices, stimulus preparation, question structure, sample interview flows for the three most common use cases (packaging, ad creative, and product concepts), and how to analyze the data once it comes back. If you have used stimulus images in interviews before, this will take your practice to the next level. If you are new to the approach, start with our stimulus-based qualitative research guide for foundational context, then come back here for the concept testing specifics.
Choosing Your Research Design: Monadic, Sequential Monadic, or Paired Comparison
Before you write a single question, you need to decide how respondents will encounter your concepts. This decision shapes everything downstream — interview length, sample size requirements, the type of data you get back, and how confidently you can compare concepts against each other.
Monadic Testing
In a pure monadic design, each respondent sees exactly one concept. They evaluate it on its own merits with no point of comparison.
When to use monadic testing:
- You want uncontaminated reactions — no anchoring effects from seeing other concepts first
- You are testing radically different directions (e.g., a playful brand identity vs. a premium one) where comparison could confuse respondents
- You need absolute metrics: "Does this concept resonate?" rather than "Does Concept A resonate more than Concept B?"
- You have enough sample size to split across concepts (you need a full cell per concept)
The tradeoff: Monadic testing requires larger total sample sizes. If you are testing four concepts and want 30 interviews per concept, that is 120 interviews total. But each interview can be shorter and more focused, which often means higher completion rates.
In an AI-moderated interview, monadic designs are straightforward to set up. You create one interview guide per concept, assign respondents randomly, and let the platform handle routing. The AI moderator never references other concepts because it genuinely does not know about them — there is no risk of accidental cross-contamination.
Sequential Monadic Testing
In sequential monadic designs, each respondent sees multiple concepts in sequence. They evaluate each one individually before any comparison questions.
When to use sequential monadic testing:
- You want both absolute and relative data from the same respondent
- Budget or timeline constraints limit your total sample size
- Concepts are variations on a theme (e.g., three label designs for the same product) rather than fundamentally different directions
- You plan to ask explicit comparison questions after individual evaluations
The tradeoff: Order effects are real. The first concept a respondent sees anchors their expectations. The second concept benefits from (or suffers from) contrast effects. You must randomize presentation order and account for order effects in analysis.
AI-moderated interviews handle sequential monadic designs particularly well. The platform can randomize concept order automatically across respondents, maintain consistent timing between stimulus presentations, and adapt follow-up probing based on how the respondent reacted to earlier concepts without the moderator fatigue that plagues human-run sequential studies.
Paired Comparison
In paired comparison designs, respondents see two concepts side by side (or in quick succession) and directly compare them.
When to use paired comparison:
- You have narrowed to a final two or three candidates and need a clear winner
- The differences between concepts are subtle and might not surface in monadic evaluation
- Stakeholders need a definitive "which one" answer
- You are optimizing within a design system (e.g., two color palettes, two headline treatments)
The tradeoff: Paired comparison tells you which concept wins the head-to-head matchup, but it does not tell you whether either concept is actually good. A respondent might prefer Concept A over Concept B while finding both mediocre. Always pair comparison data with some absolute evaluation.
For AI interviews, paired comparison works best when the platform can display both stimuli simultaneously or toggle between them on demand. The AI moderator should prompt the respondent to look at both before forming a preference, then probe into the specific dimensions driving the choice.
A Quick Decision Framework
| Situation | Recommended Design |
|---|---|
| Early-stage exploration, 4+ concepts | Monadic |
| Mid-stage refinement, 2-4 concepts, limited budget | Sequential monadic |
| Final selection between 2 concepts | Paired comparison |
| High-stakes launch decision | Monadic (for depth) + Paired comparison (for decision) |
Most teams default to sequential monadic because it balances depth and efficiency. That is a reasonable default, but do not use it blindly. If your concepts are radically different, monadic will give you cleaner data. If you just need a winner between two finalists, go straight to paired comparison.
Writing Stimulus Descriptions That Coach the AI Moderator
The AI moderator is only as good as the instructions you give it. When you set up a concept test, you are not just uploading images — you are writing stimulus descriptions that tell the AI what it is showing, what to focus on, and how to probe.
A weak stimulus description:
"Show the respondent the new packaging design and ask what they think."
A strong stimulus description:
"This is a redesigned cereal box for a kids' breakfast brand. The key changes from the current design are: (1) the mascot is now larger and centered, (2) the color palette shifted from blue/yellow to green/orange, (3) nutritional claims moved from the front panel to the side. Focus probing on: shelf standout, age-appropriateness of the mascot, and whether the health messaging feels present or absent."
The strong version gives the AI moderator context it needs to ask intelligent follow-up questions. When a respondent says "it looks healthier," the AI knows to probe whether that impression comes from the color change, the mascot redesign, or the repositioned nutritional claims — because you told it those were the key variables.
Tips for writing effective stimulus descriptions:
- State what changed. If this is a redesign, tell the AI what is different from the baseline. This helps it probe for awareness of specific changes.
- Identify the hypothesis. What are you trying to learn? "We believe the larger mascot will increase kid appeal but might reduce perceived premium quality." The AI can then probe both dimensions.
- Flag sensitive elements. If the concept includes pricing, health claims, or culturally specific imagery, note it. The AI will handle these topics with appropriate nuance.
- Specify the evaluation context. "Imagine seeing this on a grocery shelf" versus "Imagine seeing this in an online ad" changes how respondents frame their reactions.
- Set probe boundaries. Tell the AI what NOT to ask about. If the logo is not changing, instruct the moderator to redirect if respondents fixate on it.
Getting Past Social Desirability Bias
Here is the uncomfortable truth about traditional concept testing: people lie. Not maliciously — they are just being polite. When a friendly human moderator shows them a packaging design and asks "What do you think?", the social pressure to say something nice is enormous. Respondents hedge their criticism, qualify their dislike, and reach for positives even when their gut reaction was negative.
Research consistently shows that AI-moderated interviews vs human moderators produce meaningfully different response patterns on evaluative tasks. Respondents are more willing to express negative reactions, more specific in their criticism, and less likely to default to socially acceptable responses when interacting with an AI.
Why? Several mechanisms are at play:
No face to disappoint. When a human moderator clearly invested effort in preparing the session, respondents feel an implicit obligation to reward that effort with positivity. AI moderators carry no such social weight.
Perceived non-judgment. Respondents report feeling less evaluated themselves when speaking to AI. They worry less about sounding "unsophisticated" or "too critical" because the AI has no opinions of its own.
Consistency eliminates moderator signaling. Human moderators unconsciously signal their own reactions through micro-expressions, tone shifts, and follow-up phrasing. A moderator who personally likes Concept B might probe more gently on its weaknesses. AI moderators maintain perfectly consistent tone and probing depth across all concepts.
Practical ways to maximize honesty in AI concept tests:
- Open with permission to criticize. Have the AI say something like: "There are no right or wrong answers here. The team designing this genuinely wants to hear what does not work, so do not hold back."
- Ask for negatives first. After the initial reaction, probe for weaknesses before strengths. This signals that criticism is valued and prevents respondents from anchoring on positives.
- Use projective techniques. Instead of "What do you think of this design?", try "If your friend saw this on the shelf, what would they think?" Third-person framing further reduces social pressure.
- Probe vague positives. When a respondent says "It looks nice," the AI should not accept that at face value. Train it to push: "What specifically makes it look nice? Is there anything about it that does not quite work for you?"
Structuring Questions: Gut Reaction First, Reasoned Evaluation Second
The order in which you ask questions about a concept matters more than most researchers realize. The brain processes visual stimuli in two distinct phases: a fast, emotional, System 1 reaction and a slower, analytical, System 2 evaluation. Your interview structure should capture both, in that order.
Phase 1: Capture the Gut Reaction (30-60 seconds)
The moment a respondent sees your concept, their brain forms an impression in milliseconds. Your first question needs to capture that impression before rational analysis overwrites it.
Effective gut reaction prompts:
- "What is the very first thing you notice?"
- "In one or two words, how does this make you feel?"
- "What jumps out at you immediately?"
- "Without thinking too hard — what is your instant reaction?"
The AI moderator should ask one of these immediately after displaying the stimulus, then do one quick follow-up probe before moving to structured evaluation. Do not let this phase drag on — the goal is speed and spontaneity.
Phase 2: Structured Evaluation (3-5 minutes per concept)
Once you have captured the gut reaction, shift to systematic evaluation. This is where you probe specific dimensions relevant to your research objectives.
Common evaluation dimensions for concept tests:
- Appeal: Does the respondent like it? Would they pick it up, click on it, engage with it?
- Communication: What message does it convey? Is that the intended message?
- Differentiation: Does it stand out from competitors? Does it feel fresh or generic?
- Credibility: Does the respondent believe the claims or promises implied by the concept?
- Fit: Does it feel right for the brand, the category, the target audience?
- Purchase intent: Would this influence their behavior? (Use with caution — stated intent is a weak predictor)
The AI moderator should work through these dimensions conversationally, not as a checklist. If a respondent's gut reaction was "it looks cheap," the structured evaluation should probe what specifically creates that impression and whether "cheap" is necessarily negative in their category context.
Phase 3: Comparison (Sequential Monadic and Paired Comparison Only)
If respondents saw multiple concepts, the final phase asks them to compare directly. This is where you surface preference, tradeoffs, and the dimensions that drive choice.
Effective comparison prompts:
- "Having seen both designs, which one would you be more likely to pick up in a store? What tips the balance?"
- "If you could take the best elements from each, what would you keep and what would you change?"
- "Which design better fits what you expect from this brand? Why?"
The Fidelity Problem: Rough vs. Polished Stimulus
One of the most debated questions in concept testing is how polished your stimulus needs to be. Should you show respondents a finished, production-ready design? Or is a rough sketch or wireframe actually better?
The answer depends on what you are testing.
When rough stimulus wins:
- Early-stage concept exploration. Polished designs signal "this is decided" and respondents become reluctant to suggest changes. Rough sketches signal "we are still figuring this out" and invite more candid feedback.
- Testing the core idea, not the execution. If you want to know whether a product concept resonates, a polished mockup can distract respondents into critiquing visual details instead of evaluating the underlying idea.
- Multiple concepts in one session. Showing four polished designs in sequence creates evaluation fatigue. Four rough concepts feel lighter and faster to react to.
When polished stimulus wins:
- Shelf simulation. If you need to understand how a design performs in a realistic retail context, it needs to look realistic. Rough mockups cannot replicate shelf standout.
- Ad creative testing. Ads are experienced as finished products. A rough storyboard does not trigger the same emotional response as a polished animatic or finished spot.
- Final validation before launch. When you are confirming a go/no-go decision, the stimulus should match what consumers will actually see.
The hybrid approach: Start rough in early rounds, increase fidelity as you narrow options. Use AI interviews at every stage — the speed and cost advantages mean you can afford multiple rounds of testing instead of one high-stakes final test.
One important note about AI-moderated interviews: the platform handles stimulus display consistently. Every respondent sees the same image at the same size, with the same timing. There is no variation in how the moderator holds up a board or how lighting affects the printout. This consistency is a quiet but significant advantage for concept testing reliability.
Sample Interview Structures
Packaging Testing (Sequential Monadic, 3 Concepts)
Introduction (2 minutes)
- Welcome, explain the process
- "You will see three different package designs for a new product. I would like your honest reactions to each one."
- Brief category warm-up: "Tell me a bit about how you typically shop for [category]. What catches your eye on the shelf?"
Concept A Evaluation (4 minutes)
- Display stimulus: "Here is the first design. Take a moment to look at it."
- Gut reaction: "What is the very first thing that stands out to you?"
- Probe: "And how does it make you feel overall?"
- Communication: "What do you think this product is trying to tell you about itself?"
- Shelf context: "If you saw this on the shelf next to [competitor brands], would it stand out? Why or why not?"
- Target fit: "Who do you think this product is designed for?"
Concept B Evaluation (4 minutes) — Same structure, fresh stimulus
Concept C Evaluation (4 minutes) — Same structure, fresh stimulus
Comparison Phase (3 minutes)
- "Now that you have seen all three, which one are you drawn to most? What about it wins you over?"
- "Is there one that you would definitely not pick up? What puts you off?"
- "If you could combine elements from different designs, what would your ideal package look like?"
Wrap-up (1 minute)
- "Any final thoughts on what makes packaging work for you in this category?"
- Thank and close
Total time: approximately 18 minutes
Ad Creative Testing (Monadic, Single Concept)
Introduction (2 minutes)
- Welcome, explain the process
- Media consumption warm-up: "Where do you typically see ads for [category]? What kind of ads catch your attention?"
Stimulus Exposure (1 minute)
- Display ad creative (image or video)
- For video: let it play fully before any questions
- "I just showed you an ad. Let it sink in for a moment."
Gut Reaction (2 minutes)
- "What is your immediate reaction?"
- "How did it make you feel?"
- "What stuck with you most?"
Message Comprehension (3 minutes)
- "In your own words, what was the ad trying to say?"
- "Who do you think this ad is aimed at?"
- "Was there anything confusing or unclear?"
Brand Fit and Credibility (2 minutes)
- "Does this ad feel right for [brand]? Why or why not?"
- "Do you believe the message? Is there anything that feels exaggerated or off?"
Behavioral Impact (2 minutes)
- "After seeing this ad, would you do anything differently? Look into the product, mention it to someone, ignore it?"
- "Have you seen ads like this before? Does it feel fresh or familiar?"
Wrap-up (1 minute)
- "If you could change one thing about this ad, what would it be?"
- Thank and close
Total time: approximately 13 minutes
Product Concept Testing (Paired Comparison, 2 Concepts)
Introduction (2 minutes)
- Welcome, explain the process
- Category warm-up: "Tell me about how you currently handle [problem the product solves]. What works well? What frustrates you?"
Concept A Solo Evaluation (4 minutes)
- Display concept board (description, key features, price point if relevant)
- Gut reaction: "What is your first impression?"
- Value proposition: "Does this solve a real problem for you? How important is that problem?"
- Uniqueness: "Have you seen anything like this before? What feels new here?"
- Concerns: "What questions or doubts come to mind?"
Concept B Solo Evaluation (4 minutes) — Same structure
Direct Comparison (4 minutes)
- Display both concepts side by side
- "Looking at both of these, which one would you be more likely to try? Walk me through your thinking."
- "What does Concept A do better? What does Concept B do better?"
- "Is there anything in Concept A that you wish Concept B had, or vice versa?"
- "If both were available at the same price, which one wins? Does price sensitivity change that?"
Wrap-up (2 minutes)
- "What would need to be true for you to actually buy either of these?"
- "Any final reactions or thoughts?"
- Thank and close
Total time: approximately 16 minutes
How AI Handles Stimulus Display, Timing, and Follow-Up Probing
One of the underappreciated advantages of AI-moderated concept testing is the precision with which stimulus presentation is controlled. When you configure stimulus images in interviews on the Qualz platform, the system handles several things that human moderators often get wrong.
Consistent display timing. The AI presents each stimulus for a controlled duration before asking the first question. No rushing because the session is running long. No lingering because the moderator is shuffling papers. Every respondent gets the same exposure window.
Automatic order randomization. For sequential monadic designs, the platform randomizes concept order across respondents automatically. You do not need to create multiple interview guides or rely on the moderator to remember the rotation schedule.
Adaptive follow-up probing. This is where AI moderation genuinely outperforms human moderation at scale. The AI adapts its probes based on the specific words and sentiment the respondent uses. If someone says a package design "looks medical," the AI probes into what specifically creates that impression — color? typography? imagery? — without needing the moderator to have anticipated that reaction in the guide.
Cross-concept memory. In sequential monadic designs, the AI remembers what the respondent said about earlier concepts and can reference it naturally. "You mentioned that the first design felt premium. How does this one compare on that dimension?" Human moderators do this too, but inconsistently, especially in long sessions or when running many interviews back-to-back.
Consistent emotional tone. The AI does not get tired, frustrated, or bored. The fifteenth interview of the day gets the same quality of probing as the first. For concept testing specifically, this matters because moderator fatigue often leads to shallower probing on later concepts in a session and later sessions in a fieldwork period.
Analyzing Concept Test Data: From Raw Reactions to Actionable Themes
Running the interviews is only half the job. The real value comes from analysis — turning hundreds of individual reactions into a clear picture of which concepts work, which do not, and why.
Step 1: Code Initial Reactions
Start by coding gut reactions across all respondents for each concept. Create a simple taxonomy:
- Positive immediate reaction — excitement, delight, interest, attraction
- Neutral immediate reaction — indifference, confusion, mild curiosity
- Negative immediate reaction — dislike, distrust, repulsion, disappointment
The distribution of initial reactions is often more predictive than any structured evaluation metric. A concept that generates 60% positive gut reactions and 10% negative ones is in a fundamentally different position than one that generates 40% positive and 30% negative — even if their average "appeal scores" are similar.
Step 2: Extract Dimensional Themes
For each evaluation dimension (appeal, communication, differentiation, credibility, fit), identify recurring themes across respondents. What specific words and phrases come up repeatedly?
This is where AI-powered analysis shines. When you analyze open-ended responses at scale, tools can identify linguistic patterns that human coders might miss — subtle differences in how respondents describe "premium" versus "expensive," or how "simple" can be either a compliment (clean, easy to understand) or a criticism (basic, lacking sophistication).
Step 3: Map Strengths and Weaknesses Per Concept
Create a concept scorecard that maps each concept against your evaluation dimensions. For each dimension, note:
- The dominant theme (what most respondents say)
- Polarizing elements (things some respondents love and others dislike)
- Dealbreakers (things that trigger strong negative reactions in any segment)
Polarizing elements are particularly interesting. A design that splits opinion is not necessarily bad — it might be strongly resonating with your target segment while leaving non-targets cold. That is actually a good sign for differentiation.
Step 4: Identify the "Why" Behind Preferences
In comparison phases, do not just count preferences. Dig into the reasoning. What dimensions drive choice? Common patterns include:
- Shelf standout drives initial preference, but credibility drives final choice. Respondents pick the louder design first, then talk themselves into the more trustworthy one.
- Novelty wins in forced comparison but loses in purchase intent. Something can feel "fresh and different" in a comparison task but "too risky" when real money is involved.
- Specific elements anchor overall preference. One particular color choice, one headline phrase, or one image can dominate the entire evaluation. Identifying these anchor elements helps you optimize rather than start from scratch.
Step 5: Build the Recommendation
Your final output should go beyond "Concept B wins." Structure your recommendation around:
- The clear winner (if there is one) and the specific reasons it wins
- Elements from losing concepts worth incorporating — concept testing should inform optimization, not just selection
- Segments that diverge from the overall pattern — if younger respondents prefer Concept A while older ones prefer Concept B, that is critical context
- Risk factors — anything that could undermine the winning concept in market (polarizing elements, credibility concerns, competitive vulnerability)
- Recommended next steps — does the winner need further refinement and testing, or is it ready for launch?
Making Concept Testing a Continuous Practice
The traditional approach to concept testing treats it as a gate: design concepts, test once, pick a winner, move to production. AI-moderated interviews make a different model possible — continuous, iterative concept testing where you test early, test rough, refine based on data, and test again.
The economics work because AI interviews cost a fraction of traditional moderated sessions and can be fielded in days rather than weeks. The quality works because AI moderation maintains consistency across hundreds of interviews in ways that human moderation teams cannot match.
If you are running concept tests today — whether for packaging, ad creative, product concepts, or anything else that benefits from honest human reactions — AI-moderated interviews are the fastest path to better data.
Ready to run your first AI-moderated concept test? Book a demo and we will walk you through setting up a study with your actual concepts. See firsthand how the AI moderator handles stimulus presentation, adaptive probing, and cross-concept analysis — with your real materials, not a canned demo.