The pitch is seductive: instead of spending weeks recruiting hard-to-reach beneficiaries across three countries, just generate synthetic participants that mirror your target population. Faster timelines, lower costs, no IRB headaches.
If you work in impact assessment, program evaluation, or development consulting, you have probably encountered this idea — either from a vendor demo, a conference panel, or a well-meaning colleague who read about synthetic users in a UX research context. And your instinct was probably a mix of curiosity and skepticism.
That instinct is correct. Synthetic participants have legitimate, valuable applications in impact assessment. They also have hard boundaries that, if crossed, can undermine the very purpose of the work you do. The challenge is knowing where those boundaries are.
This post is not a sales pitch for synthetic participants, nor a blanket dismissal. It is a practitioner's guide to understanding what they actually are, where they genuinely help, where they absolutely do not, and how to make the call for your specific engagement. If you are an impact evaluator, development consultant, or program manager considering AI-generated research subjects, this is the framework you need.
What Synthetic Participants Actually Are
Let's start with precision, because the terminology is loose and getting looser.
A synthetic participant is an AI-generated persona that simulates the responses, behaviors, or decision patterns of a human research subject. The underlying technology typically works in one of three ways:
LLM-based persona simulation. A large language model is prompted with demographic, psychographic, and contextual parameters ("You are a 45-year-old female farmer in rural Tanzania who has been using a drip irrigation system for two years") and then generates responses to research questions as if it were that person. The quality of the output depends heavily on the specificity of the prompt and the model's training data coverage for that population.
Agent-based modeling with AI augmentation. More sophisticated implementations use structured agent-based models where synthetic participants operate within defined behavioral rules, constraint sets, and interaction dynamics. The AI component adds natural language generation on top of the behavioral model, producing more realistic qualitative outputs.
Data-driven synthetic generation. When you have existing datasets from real participants, statistical and ML techniques can generate new synthetic data points that preserve the distributional properties of the original dataset without containing any actual individual's data. This is closer to synthetic data generation than synthetic participants per se, but the terms frequently get conflated.
Each approach has different strengths, different failure modes, and different appropriate use cases. Conflating them — as much of the current discourse does — leads to bad decisions.
For a deeper comparison of how synthetic and human participants differ across research contexts, see our analysis of synthetic participants versus human participants.
Where Synthetic Participants Add Legitimate Value in Impact Assessment
Let's be specific about the use cases where synthetic participants genuinely help. These are situations where the alternative is not "just go recruit real people" — it is "fly blind, delay the project, or settle for weaker instruments."
Pre-Testing Research Instruments
This is the single strongest use case for synthetic participants in impact assessment, and it is underutilized.
Before you deploy a 40-question survey to 500 beneficiaries across three regions, you need to know whether your questions actually work. Do respondents interpret them as intended? Are the response scales appropriate? Do the skip patterns make sense? Are there cultural or linguistic issues that will produce garbage data?
Traditionally, you pre-test with a small convenience sample — maybe 10-15 people from the target population. This is good practice but expensive, time-consuming, and often logistically difficult when your beneficiaries are in remote areas.
Synthetic participants can serve as a rapid, low-cost first pass. Generate 50-100 synthetic respondents that match your target demographics, run them through your instrument, and analyze the results for:
- Floor and ceiling effects — are all synthetic responses clustering at one end of a scale?
- Comprehension issues — do the synthetic respondents' open-ended explanations suggest they interpreted the question differently than intended?
- Skip logic failures — do the branching patterns produce dead ends or nonsensical paths?
- Missing response options — do synthetic respondents consistently try to express something your fixed options do not capture?
This does not replace human pre-testing. It precedes it. You catch the obvious instrument problems with synthetic participants, fix them, and then use your limited pre-test budget with real participants to catch the subtle cultural and contextual issues that AI cannot simulate.
If you are working on adaptive survey design with branching logic, synthetic pre-testing can save weeks of iteration by stress-testing complex survey paths before they reach a single real respondent.
Stakeholder Simulation and Scenario Planning
Impact assessments routinely involve stakeholder analysis — mapping who has power, who has interest, and how different groups are likely to respond to program changes. Tools like stakeholder equity audit frameworks provide structure, but the underlying analysis still requires judgment calls about stakeholder behavior.
Synthetic participants can model stakeholder dynamics in ways that are genuinely useful for scenario planning:
- Policy change simulation. "If we shift the subsidy from input-based to output-based, how do different farmer segments respond?" Generate synthetic stakeholders representing each segment and simulate their decision-making.
- Power-interest matrix stress testing. You have mapped your stakeholders on a power-interest grid. Now use synthetic participants to test your assumptions — does a low-power stakeholder group actually have more influence than you assumed when you model their network effects?
- Conflict anticipation. Before a multi-stakeholder workshop, simulate the discussion dynamics between synthetic representatives of each group. Identify likely friction points and prepare facilitation strategies.
The key here is that you are not using synthetic participants as evidence. You are using them as a thinking tool — a way to pressure-test your own assumptions before engaging real stakeholders. The output is hypotheses to validate, not findings to report.
Filling Temporal and Access Gaps
Some impact assessment contexts involve populations you genuinely cannot reach — or cannot reach again:
- Post-conflict zones where security prevents fieldwork
- Historical program evaluations where the original beneficiaries have dispersed
- Rapid-onset emergencies where you need preliminary analysis before field access is possible
- Populations with extreme research fatigue who have been surveyed dozens of times by different agencies
In these cases, synthetic participants generated from existing datasets about similar populations can provide directional insights that are better than nothing — provided they are explicitly flagged as synthetic and not presented as primary evidence.
A development consultant doing AI-powered impact assessment work can use synthetic participants to build a preliminary analytical framework that gets refined once real data becomes available. The synthetic data shapes the questions you ask, not the answers you report.
Training and Capacity Building
If you are training junior evaluators or building organizational capacity for qualitative research, synthetic participants are excellent practice material. New researchers can:
- Practice conducting interviews with AI-generated respondents
- Develop coding skills on synthetic transcripts before touching real data
- Test their analytical frameworks against controlled scenarios
- Build confidence with semi-structured interviewing techniques
This use case has almost no downside and significant upside for organizations investing in research democratization — extending research capabilities beyond a small team of specialists.
Where Synthetic Participants Must Not Be Used
Now for the hard boundaries. These are not "proceed with caution" situations. These are "do not do this" situations.
As a Replacement for Beneficiary Voices
This is the bright line. Impact assessment exists to understand the lived experiences of the people affected by programs and policies. Synthetic participants, no matter how sophisticated, cannot replicate lived experience. They can approximate demographic patterns. They cannot tell you what it actually feels like to walk four kilometers for water, or how a microloan changed a family's power dynamics, or why a health intervention was rejected by a community despite clear evidence of its effectiveness.
When donors fund an impact assessment, they are paying for ground truth. When an evaluator presents findings, the implicit contract is that those findings reflect what real people said and experienced. Substituting synthetic responses — even partially, even with disclosure — violates that contract in ways that can undermine trust in the entire evaluation ecosystem.
Organizations working to preserve authentic beneficiary voices while using AI tools understand this distinction: AI should amplify real voices, not fabricate new ones.
As Primary Evidence in Evaluation Reports
Your evaluation report goes to donors, program managers, and policymakers who make resource allocation decisions based on your findings. Those decisions affect real communities. If your "finding" that "73% of beneficiaries reported improved water access" is based on synthetic participants rather than actual beneficiaries, you have introduced a fiction into a decision-making process with real consequences.
This applies even when synthetic data is clearly labeled. Decision-makers under time pressure scan executive summaries, not methodology annexes. The finding will travel without its caveats.
For Sensitive or Marginalized Populations
Generating synthetic participants that simulate refugees, abuse survivors, indigenous communities, or other marginalized populations carries specific ethical risks:
- Stereotyping and flattening. LLMs trained on existing text will reproduce dominant narratives about marginalized groups, potentially reinforcing stereotypes rather than surfacing authentic perspectives.
- Erasure. Using synthetic versions of marginalized voices implicitly says "we do not need to hear from you directly" — which is precisely the dynamic that impact assessment is supposed to counteract.
- Consent issues. If synthetic participants are generated from datasets that originally involved real marginalized individuals, those individuals did not consent to having their data used to create AI simulations of people like them.
The ethical considerations around AI and sensitive data in qualitative research apply with even greater force when the data is being used to generate synthetic human subjects rather than just analyze existing responses.
When Validation Is Impossible
Synthetic participants are only as good as your ability to validate their outputs against reality. If you have no way to check whether synthetic responses bear any resemblance to what real participants would say — because you have no prior data from the population and no ability to collect any — then synthetic participants are not "filling a gap." They are generating plausible-sounding fiction.
The impact of using synthetic users depends entirely on the validation loop. No validation, no value.
GDPR and Data Protection Implications
For consultants working in or with the EU — which includes a large proportion of impact assessment work — GDPR creates specific considerations around synthetic participants that are frequently misunderstood.
Synthetic data generated from real participant data is still subject to GDPR at the generation stage. The fact that the output is synthetic does not retroactively anonymize the input. If you use real beneficiary interview transcripts to train or prompt a model that generates synthetic participants, the processing of those real transcripts must comply with GDPR — including lawful basis, purpose limitation, and data minimization.
Synthetic participant outputs may still constitute personal data if they are re-identifiable. If your synthetic participant profile is specific enough that someone could link it back to a real individual (e.g., "a 52-year-old female village chief in a village of 200 people in district X"), the synthetic output may itself be personal data under GDPR's broad definition.
Data Protection Impact Assessments (DPIAs) may be required. If your use of synthetic participants involves processing real personal data as input, or if the synthetic outputs could affect real individuals (e.g., by influencing program design for their community), a DPIA is likely necessary under Article 35.
For a comprehensive treatment of GDPR compliance in qualitative research contexts, including data processing agreements and anonymization standards, see our GDPR compliance guide for qualitative research.
Practical steps for GDPR-compliant use of synthetic participants:
- Document your lawful basis for processing any real data used to generate synthetic participants
- Apply k-anonymity or differential privacy techniques to input data before using it for synthetic generation
- Assess re-identification risk of synthetic outputs, especially for small or distinctive populations
- Include synthetic participant methodology in your DPIA if one is required for the project
- Inform original participants if their data will be used for synthetic generation, as part of your consent process
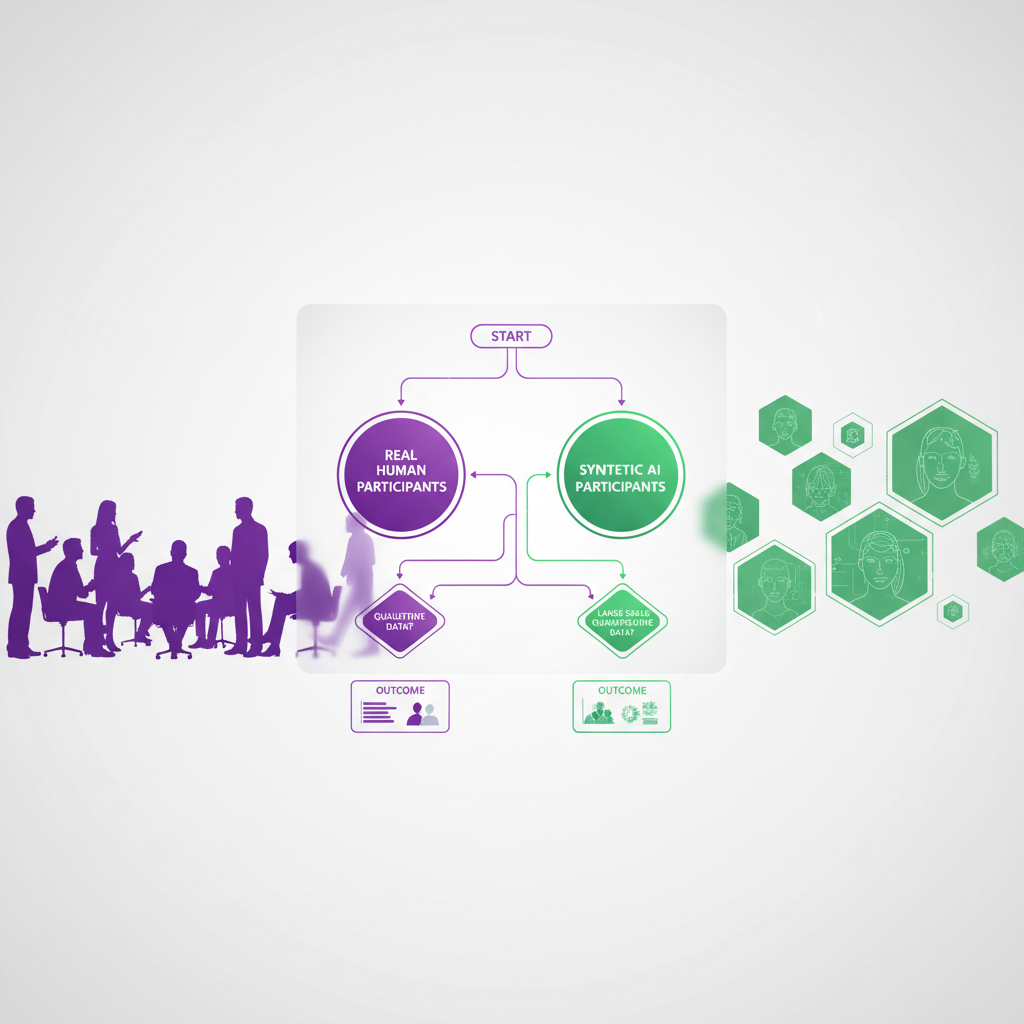
Combining Synthetic and Real Participants: A Practical Framework
The most productive approach is not synthetic OR real — it is a deliberate combination where each type serves a specific function in your research design.
The Layered Approach
Layer 1: Synthetic-led instrument development (Weeks 1-2)
Use synthetic participants to pre-test and refine your data collection instruments. Generate 50-100 synthetic responses, analyze for instrument quality issues, revise, repeat. Cost: minimal. Risk: minimal. Value: significant time savings in later stages.
Layer 2: Synthetic-led scenario modeling (Weeks 2-3)
Use synthetic stakeholder simulations to develop your analytical framework and generate hypotheses. Map expected patterns, identify key variables, and design your sampling strategy based on where you expect the most variation.
Layer 3: Real participant data collection (Weeks 3-6)
Conduct your actual fieldwork — interviews, surveys, focus groups — with real participants. This is the core of your assessment. No synthetic substitutes.
Layer 4: Synthetic-augmented analysis (Weeks 6-8)
After collecting real data, use synthetic participants to stress-test your emerging findings. "If our finding is X, would a synthetic population with different characteristics produce similar results?" This is sensitivity analysis, not evidence generation.
Layer 5: Validation and triangulation (Weeks 7-8)
Compare your synthetic pre-testing predictions against actual data. Where did the synthetic participants get it right? Where did they diverge? This meta-analysis improves your use of synthetic participants in future engagements and provides transparency for your methodology annex.
This layered approach — particularly when combined with an AI-powered qualitative analysis workflow — lets you capture efficiency gains from synthetic participants without compromising the integrity of your primary data collection.
Documentation Requirements
For every engagement that uses synthetic participants in any capacity, document:
- Which stages used synthetic versus real participants
- What parameters defined your synthetic participant profiles
- What model and version generated the synthetic responses
- What validation was performed against real-world data
- What limitations apply to any synthetic-derived insights
This documentation is not optional. It is your methodological integrity. Donors are increasingly savvy about AI use in evaluation, and proactive transparency builds trust far more effectively than retroactive disclosure.
The Decision Framework: When to Use vs. When Not To
Use this decision tree for any engagement where synthetic participants are being considered:
Step 1: What is the purpose?
- Instrument development / pre-testing → Likely appropriate
- Scenario planning / hypothesis generation → Likely appropriate with caveats
- Training / capacity building → Almost always appropriate
- Primary data collection → Not appropriate
- Evidence for evaluation findings → Not appropriate
Step 2: Is validation possible?
- You have existing data from this population to validate against → Proceed with caution
- You will collect real data later to validate against → Proceed with clear documentation
- No validation pathway exists → Do not use synthetic participants
Step 3: What is the population sensitivity?
- General population, low-risk topic → Standard precautions sufficient
- Vulnerable or marginalized population → Additional ethical review required; default to not using unless clear justification exists
- Sensitive topics (violence, health, displacement) → Do not use synthetic participants
Step 4: What are donor and stakeholder expectations?
- Donor has explicitly approved synthetic participant methodology → Document and proceed
- Donor has no stated position → Disclose your intended methodology proactively before proceeding
- Donor requires primary data from real beneficiaries → Do not use synthetic participants as any form of substitute
Step 5: Does your team have the technical capacity?
- You understand the model's training data, limitations, and bias patterns → Proceed
- You are treating the AI as a black box → Stop and build understanding before proceeding
What This Means for Independent Consultants and Program Managers
If you are an independent consultant doing program evaluation and impact assessment, synthetic participants are a tool — not a paradigm shift. They can meaningfully reduce the time and cost of instrument development and scenario planning. They cannot reduce the time and cost of actually listening to the people your programs are supposed to serve.
For program managers considering AI in stakeholder engagement, synthetic stakeholder simulations can sharpen your engagement strategy. But the engagement itself must involve real stakeholders with real agency.
For environmental researchers and specialists working in contexts like water management where community perspectives are integral to program success, synthetic participants can help you prepare better research instruments — but the community voice must remain authentic and central to your findings.
The bottom line: use synthetic participants to get smarter before you go into the field. Do not use them to avoid going into the field.
Getting Started Without Overcommitting
If you want to experiment with synthetic participants in your practice, start small:
- Pick a completed project where you have real data. Generate synthetic participants for the same population and compare outputs. This gives you a no-risk calibration of synthetic quality for your specific context.
- Use synthetic pre-testing on your next instrument. Before your next survey deployment, generate 50 synthetic responses and analyze them for instrument quality. Compare the issues you find with what emerges from your human pre-test.
- Document everything. Even in your experimental phase, build the documentation habits that will matter when you use synthetic participants in a live engagement.
- Be transparent with clients. If you plan to use synthetic participants in any capacity — even for instrument development — disclose it. Most clients will appreciate the innovation. The ones who object will tell you something important about their expectations.
Impact assessment is fundamentally about accountability — accountability of programs to the communities they serve, and accountability of evaluators to the truth of what they find. Synthetic participants can make you a more efficient, better-prepared evaluator. They cannot make you a more accountable one. That part is still on you.
Ready to integrate AI into your impact assessment workflow while keeping real participant voices at the center? Qualz.ai helps independent consultants and evaluation teams analyze qualitative data faster — with full audit trails, GDPR compliance, and the analytical rigor your donors expect.